I highly recommend looking at this first:
Introduction:
In this post, I’ll cover doing distributed binary analysis with python-rq, redis, and NFS share. I’ll keep the analysis really really simple. We’ll be getting some other PE info. If you look at Resources/Similar Projects section. You’ll find similar and more stable projects as well.
Problem:
I have bunch of files I need to analyze and I want to distribute analysis amongst different servers.
Solution:
As mentioned in previous blog post linked above, I’ll be using Python-rq. Python-rq works with Redis. I’ll also be utilizing NFS for sharing files across multiple worker nodes and pefile for getting PE information.
Setup:
I have three machines with Ubuntu 10.04 on them. Two machines are Workers and one machine is Redis server and a job creator. Additionally, I have NFS server where I will have my binary files and python scripts.
WORKER1 - 10.0.0.14
WORKER2 - 10.0.0.8
DIST - 10.0.0.9
NFS Server - 10.0.0.11:/mnt/storage/malware (Using Freenas)
Install screen or tmux on everything!
We’ll need to install required software on DIST.
I ran:
apt-get update && apt-get install -y python-pip redis-server && pip install rq rq-dashboard
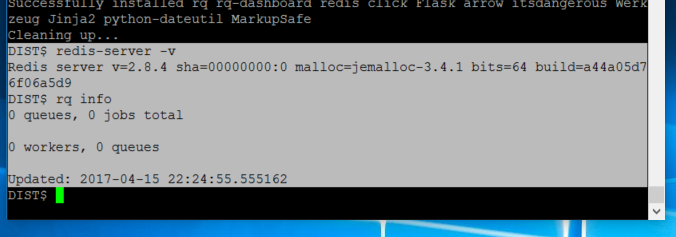
And to confirm everything was installed:
redis-server -v
rq info
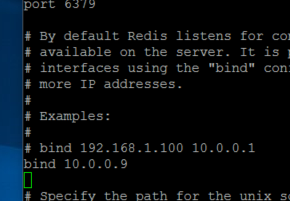
Edit Redis-server configuration and make it bind to 10.0.0.9.
Config file: /etc/redis/redis.conf
Locate bind 127.0.0.1 and change it 10.0.0.9.
Run the following to restart redis-server:
service redis-server restart
We will also start rq-dashboard on Dist.
Run the following command in a screen session:
rq-dashboard -H 10.0.0.9
It should start a webserver on port 9181.

On Worker1 and Worker2 we’ll need python-pip and rq. Tip: If you’re using VM’s or cloud, just configure one worker node then deploy copies.
I ran:
apt-get update && apt-get install -y python-pip && pip install rq
And to confirm rq was installed correctly:
rqworker -u redis://10.0.0.9:6379

Now we’ll get NFS share setup.
On worker nodes and dist, I created /share directory where I’ll mount the NFS share.
Also, I forgot this earlier. We need NFS client.
Run the following on worker nodes and dist:
apt-get install -y nfs-common
To mount the NFS file system run (if you’re going to be setting up something stable, edit your fstab file):
mount -t nfs 10.0.0.11:/mnt/storage/malware /share
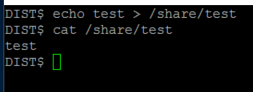
Run the following to make sure NFS share permissions are set correctly:
echo test > /share/test
cat /share/test
On my worker nodes, I need pefile library. I ran:
pip install pefile
I created /share/malware folder. I’ll put my samples in that folder. If you’re looking for samples to play with check out: https://www.reddit.com/r/Malware/comments/615el6/malware_samples/ :-D

Now we can start writing code to do the analysis.
Code:
I recommend installing ipython on one of your worker nodes and dist node. It makes debugging and testing much easier.
I will be putting my code in /share. We will be running rqworker in that directory as well. Putting code on NFS server makes updating easier.
We’ll need code for processing part and job distribution part.
For processing, I have a function that takes in full path to the PE file and looks at some properties and writes the results to a text file. Code I used is from pefile example document (linked below).
Processing code: https://github.com/ITLivLab/DistFileProcPy/blob/master/process_pe.py
My file name is process_pe.py and function for processing the files is procpe(FILENAME).
Now we can work on job distribution code. My code is really simple for now. I’ll take full file path as argument, add it to queue, and not wait for results. (procpe returns True and False)
Job distribution code: https://github.com/ITLivLab/DistFileProcPy/blob/master/dist.py

Analysis:
We need to cd into /share and run rqworker command (you can run rqworker multiple times on the same machine):
rqworker -u redis://10.0.0.9:6379
On dist, we can cd into /share as well and run the following:
for file in /share/malware/*; do python dist.py $file; done
We can see our jobs in rq-dashboard.

After everything is done being processed, we can see results:

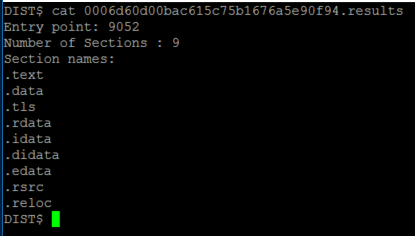
Conclusion/Improvements:
This was a good way for me to learn to distribute things using Python. I’m aware of some of the Apache projects that do stuff like this as well. I feel more comfortable with Python right now. Also, setup for this is really simple.
As you can tell already. I’m not a professional programmer and I’m lazy. There are several problems with this design too. I think I can add multithreading or multiprocessing to make workers process more data. Code is on github, feel free to fork and improve it. If you do, please leave a comment.
I do plan on running this at my university and adding more features. I'll keep updating the code on Github.
I do plan on running this at my university and adding more features. I'll keep updating the code on Github.
If there are alternative methods or I made some mistakes in the post, leave a comment.
(As you can see from the timestamps in screenshots, I wrote this at night. Expect typos)
(As you can see from the timestamps in screenshots, I wrote this at night. Expect typos)
Thanks.
Resources/Similar Projects: