Typically, the winner information is presented as shown below:
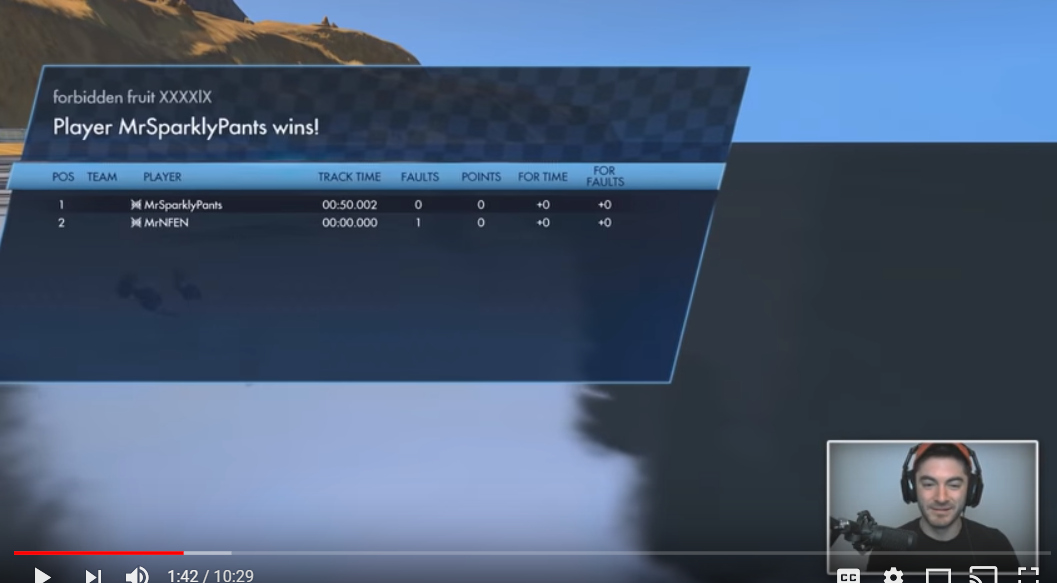
(from video: https://www.youtube.com/watch?v=W528UyfC42k)
As you can see in the screenshot above, there is a specific area where map and winner information is presented. To extract that specific information, I used Python, OpenCV, and Tesseract OCR. OpenCV will allow me to process the videos and Tesseract OCR will be able to extract the information for me.
OpenCV allows you to view a file frame by frame and the code example is shown here: https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_gui/py_video_display/py_video_display.html#playing-video-from-file
Here's what it looks like when I process the video:
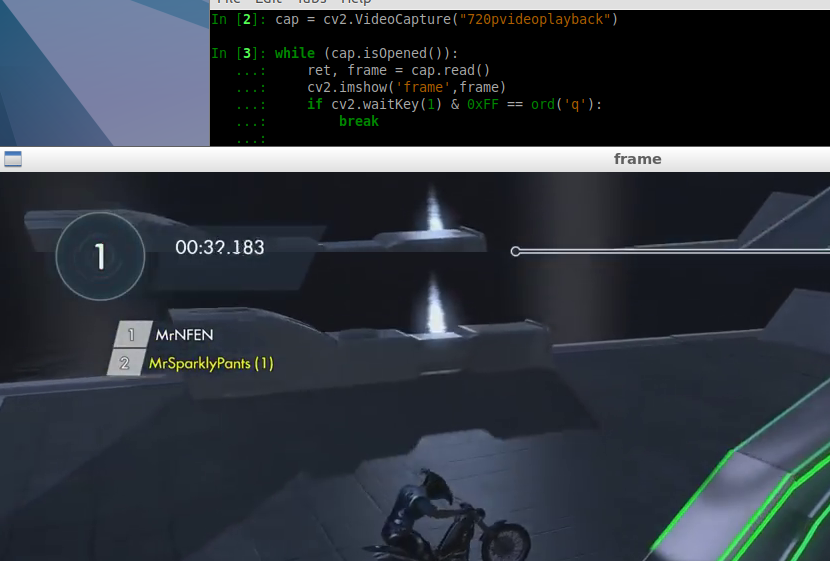
In the screenshot above, we have 720p video (after some testing, I found out that 720p was probably the best choice for this) and frame extracted from that video. Since I'm just interested in the area of the frame that contains map and winner information I decided to crop that area.
This post has more information on how to crop: https://www.pyimagesearch.com/2014/01/20/basic-image-manipulations-in-python-and-opencv-resizing-scaling-rotating-and-cropping/
After cropping the frame appears as shown below:
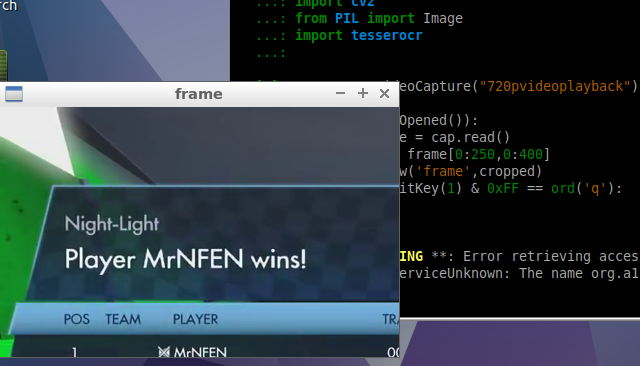
After I had the cropping part working correctly, I decided to do OCR with tesseract. OpenCV allows you to convert the frame to grayscale or black and white. I tested OCR with both gray and black and white frames and it did not make too much of a difference in the output from OCR.
To have tesseract OCR analyze the frame, the following has to be done:
image = Image.fromarray(frame)
str_out = tesserocr.image_to_text(image)
Here are some issues with doing OCR that I had while doing this:
- You'll be extracting information about the current race, such as time, player name, and faults.
- Processing each frame is a bad idea and wastes a lot of resources
- Looking for "wins" and "Player" in the OCR output is a good idea but you may see that every frame for that one map (for example, seeing frame 99 then 100 with similar OCR output)
- If you look for "wins" and "Player" and skip frames, you may end up skipping too much and missing results
- Sometimes winner players information is picked up but not the map information
I process every 50 frames. If OCR of the frame contains "wins" then I process OCR data further. Check each line from OCR output, if the line contains "wins" and "Player" then figure out the player who won. If the line does not contain "wins" and "Player" then it's obviously a map name. Concatenate map name, player name, and video name into one variable and print it. There is another part that keeps track of frame number that we successfully extracted the map and the player information out of. Full extraction in OCR frame only happens if the new frame is 500 frames after the last successful extraction frame number. This is implemented so after 50 frames, we don't re-extract the same map and player information but at the same time, since we're processing every 50th frame, we won't miss an outcome of a map. The process is hard to explain so definitely look at the code.
The results:
165 videos were processed. 670 maps were seen by the script.
NFEN won 291 maps. CaptainSparklez won 371 maps. Mark/YYFakieDualCom (script didn't look for this username) won 8 maps.
Script and the results are posted on Github: https://github.com/BoredHackerBlog/TrialsFusionOCR
Anyways, this was a fun and interesting side project for me. There are definitely ways to improve this. For example, OCR isn't perfect and tesseract could have been trained to extract better data. Also, the code could probably be optimized or be written in a different language like C++ or Golang to get better performance.