Introduction:
In this post, I’ll cover crawling and indexing hidden sites. This might be useful for research. Also, you can have your own search engine just to play with. There are already couple of projects that have done this, one of the well known ones is Ahmia. This post does not make any improvements on that project. I just wanted to have something of my own. I might end up doing some research project with the data but I can’t think of any ideas right now.
Software:
Ubuntu Server 14.04 64-bit - I have a Proxmox template that I just clone. You should be able to use newer versions.
Apache Nutch 1.13 - There are two versions of Nutch. 1.x and 2.x. Version 1.13 was recently released so I’m just using that.
Elasticsearch 2.3.3 - Nutch 1.13 works correctly with version 2.3.3.
Kibana 4.5.4 - According to the the support matrix here: https://www.elastic.co/support/matrix#show_compatibility Kibana 4.5.4 works with Elasticsearch 2.3.3.
Docker - We’ll use rotating HAProxy -> Tor container that’s here https://github.com/mattes/rotating-proxy This will basically distribute our requests over multiple tor connections.
Overview:
We will start Rotating Proxy. Nutch will be configured to use Rotating Proxy port and use Elasticsearch to save data. We will also configure it to only crawl .onion domains. We will provide seed URL list to Nutch. Seed URLs is where Nutch will start begin crawling. Nutch will take the data and put it in Elasticsearch. The data we’ll get is text data. We won’t be getting any images. Finally, we will use Kibana to browse the data and do our searches.
Installation:
We will install Java first.
apt-get update
apt-get install python-software-properties
add-apt-repository ppa:webupd8team/java
apt-get update
apt-get install oracle-java8-installer -y
Add the following line into your /etc/environment file:
JAVA_HOME="/usr/lib/jvm/java-8-oracle"
Now we’ll install Docker and pull the rotating proxy container.
curl -fsSL get.docker.com -o get-docker.sh
sh get-docker.sh
docker pull mattes/rotating-proxy:latest
Next, we’ll download and configure Nutch.
DO NOT DO THIS! GO DOWN TO “Fix” SECTION AND COMPILE NUTCH INSTEAD!
tar xvfs apache-nutch-1.13-bin.tar.gz
We need to modify the following values inside of apache-nutch-1.13/conf/nutch-site.xml:
http.agent.name needs to be Mozilla/5.0. You can modify other http.agent values if you need to.
http.proxy.host needs to be 127.0.0.1 since we’re running Rotating proxy container on the same machine.
http.proxy.port needs to be 5566.
elastic.host should be set to 127.0.0.1 as well since we’re running that on the same machine.
That’s all the things we need to modify. You can modify other settings to your likings if you want.
We need to edit apache-nutch-1.13/conf/regex-urlfilter.txt too. We just want to following hidden sites (.onion).
Comment out the bottom line, which is ‘+.’
Add the following line underneath
Now we need to generate our seed URL file. For our seed, we’ll just use Hidden Wiki. You can also use hidden site lists we find in other places such as Ahmia or Pastebin.
Inside apache-nutch-1.13/bin, create a folder called urls. Add seed.txt file which contains the following line:
That’s all. We’re done with Nutch for now.
Finally, Elastic and Kibana.
tar xvfs kibana-4.5.4-linux-x64.tar.gz
unzip elasticsearch-2.3.3.zip
We just need to configure Kibana. In kibana-4.5.4-linux-x64/config/kibana.yml, we just need to uncomment server.host: "0.0.0.0".
The binary file for Kibana is kibana-4.5.4-linux-x64/bin/kibana
The binary file for Elasticsearch is elasticsearch-2.3.3/bin/elasticsearch

Running everything:
First we’ll get proxy up and running and test it out.
docker run -d -p 5566:5566 -p 4444:4444 --env tors=25 mattes/rotating-proxy
curl --proxy 127.0.0.1:5566 ifconfig.co
Start elasticsearch and then kibana:
./elasticsearch
./kibana
Kibana should run on 0.0.0.0:5601. You should be able to visit the IP address of the machine you’re working on and port 5601 via a browser and see Kibana load.
Finally, we can begin crawling with Nutch.
Inside of bin folder under Nutch, there is a crawl script.
These are the arguments you can provide:
crawl [-i|--index] [-D "key=value"] [-w|--wait] <Seed Dir> <Crawl Dir> <Num Rounds>
We’ll run:
./crawl -i urls/ onioncrawl/ 3
-i so we can index our data
urls/ is our directory with seed.txt file.
onioncrawl/ is the directory Nutch will create to store data
3 is the number of rounds. It’s basically the depth. Lower number means low depth.
In Kibana webUI, go to Settings and add ‘nutch’ as your index and set time-field name to ‘tstamp’. Click ‘Create’. Go to Discover page and you should see some data.
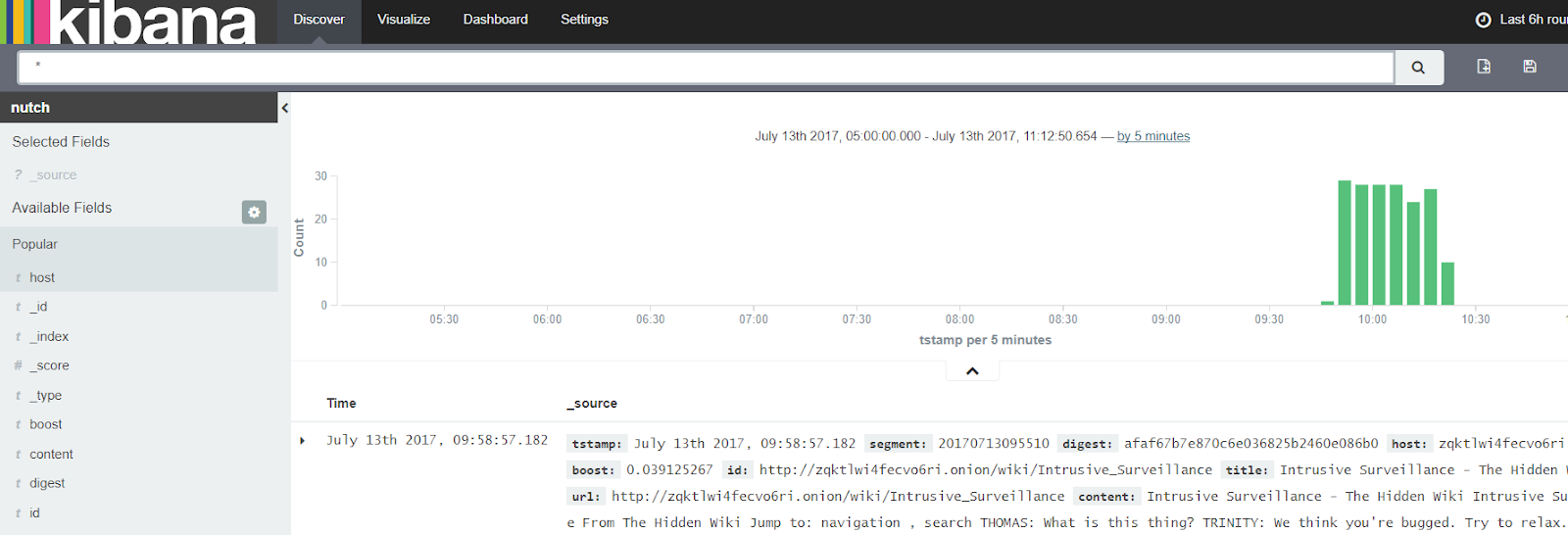
Screenshots!:
This is what Kibana looks like.
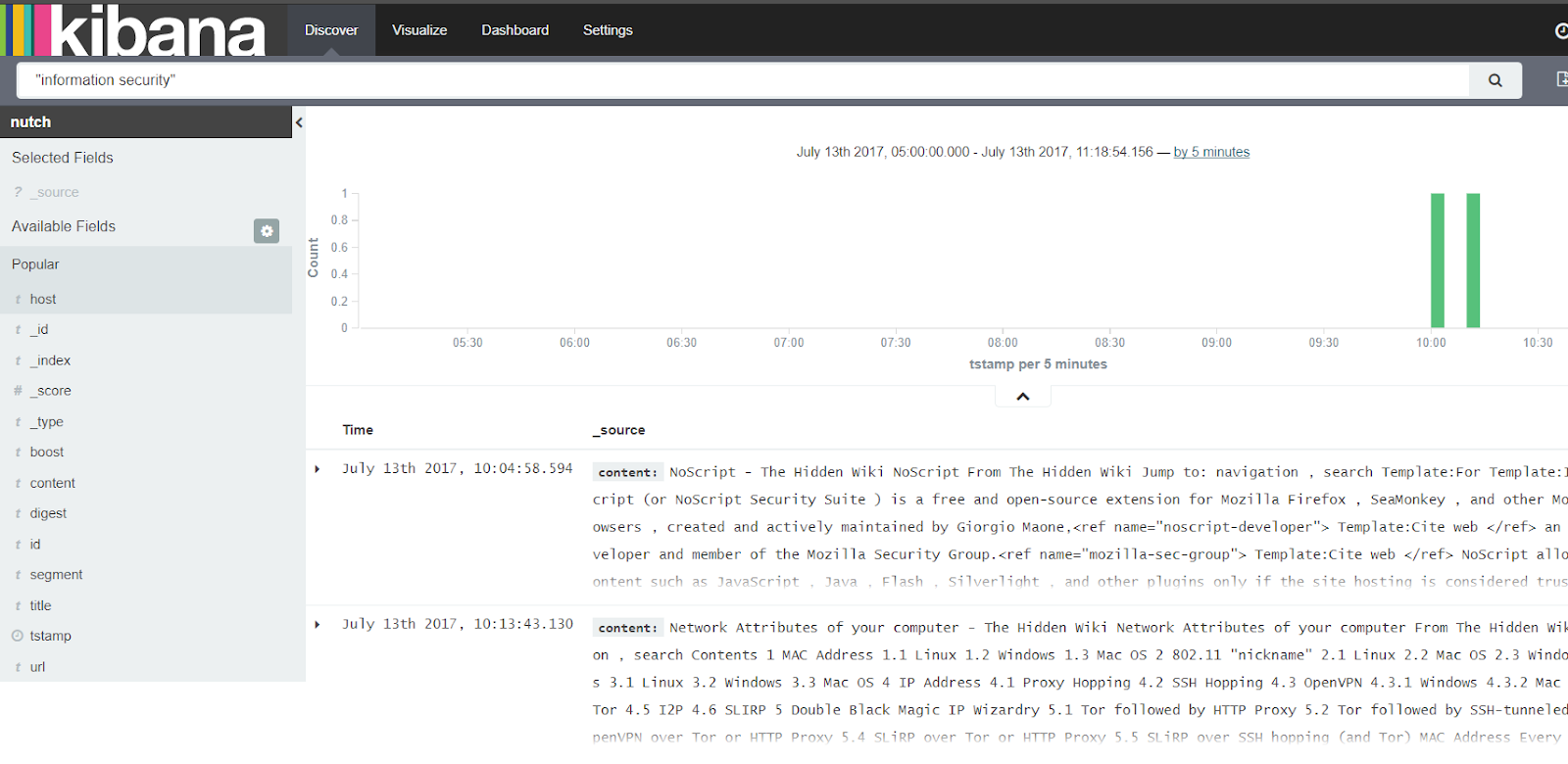
I searched for “information security”
Content containing “information security”
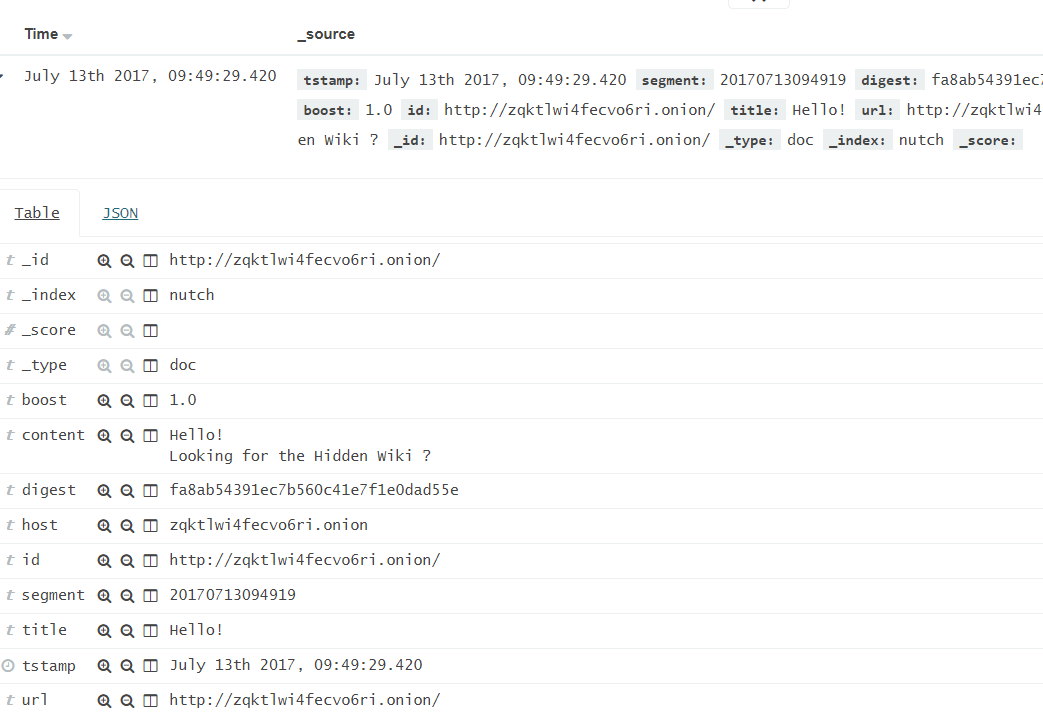
This shows the fields that are indexed.
Problems:
I had couple of issues. First thing is, I haven’t optimized Nutch and Elasticsearch. I am running everything on a single machine. This may hurt the performance. Optimization is something I’ll look into in the future. Second problem I had was with Nutch crashing while putting the data on Elasticsearch. Here’s the error:
ERROR CleaningJob: java.io.IOException: Job failed!
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:865)
at org.apache.nutch.indexer.CleaningJob.delete(CleaningJob.java:174)
at org.apache.nutch.indexer.CleaningJob.run(CleaningJob.java:197)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.nutch.indexer.CleaningJob.main(CleaningJob.java:208)
Look at “Fix” section.
In the past I was able to crawl about 10 gigs of data without any issues, at that time I didn’t have Elasticsearch part working. If there are improvements that can be made, leave them in the comments. I can’t say that I’m too familiar with Nutch. I was just familiar enough to get it running.
apt-get install ant
git clone https://github.com/apache/nutch
cd nutch; ant runtime
Go make some coffee.
“BUILD SUCCESSFUL” is what you’re looking for.
cd runtime/local
In this folder, you’ll see conf and bin. Copy nutch-site.xml and regex-urlfilter.txt into the conf folder. Copy the urls folder into the bin folder.
We can delete the old nutch Elasticsearch index by running this:
curl -XDELETE 'localhost:9200/nutch?pretty'
You’ll have to run crawl a bit differently since the argument format is different.
crawl [-i|--index] [-D "key=value"] [-w|--wait] [-s <Seed Dir>] <Crawl Dir> <Num Rounds>
We’ll run:
./crawl -i -s urls/ onioncrawl/ 4
I haven’t had another crash like I did previously! Final message I got was this “Finished loop with 4 iterations”
Resources:
I used a lot of different resources to figure out what I was doing. I’ll put bunch of them here. You may or may not find all of them useful.
You don’t have to use any files from the repo, I am uploading them to make setup easier for myself in the future.
Resources for this research are provided by Living Lab IUPUI (http://livlab.org/) and IUPUI (https://www.iupui.edu/)
It’s always nice to have fast internet connection through the university. :-D
Leave a comment if there are mistakes in this post.