I was a TA in a forensics class during Spring. I created an extra-credit assignment for the class. The assignment is below:

I selected TeamViewer because I didn't see any tool to recover this file type.
The goal was to make students figure out the file structure for TeamViewer recording files, figure out what data to extract, and learn/apply programming skills.
Solution:
First thing to do is to discover what Teamviewer file format
is like.
I downloaded some TVS files from the internet. Alternatively,
you can create a teamviewer session and record it, then save it as well.
I opened them in a hex editor.

Both files begin with TVS as header then there is some
metadata then there is BEGIN. Metadata is information about the recording.
So our format so far is TVS (METADATA) BEGIN.

Both files have END and base64 string at the bottom. When carving automatically, it’s hard to figure out when the base64 string ends. It’s much easier to just look for TVS header and END footer.
To see if I can open file that does NOT contain base64 after END, I modified the file and removed base64.

I saved the file as nobase64.tvs.

And opening and playing the modified file does work!
So information we have to look for and extract:
TVS (header) | metadata | BEGIN | DATA | END (footer)
I created a fake image by just dumping urandom + tvs file + urandom into one file.
In python, I can open and read file in binary mode and start looking for hex data.

So now, I have to go through 0 to 361286618 and look for TVS, BEGIN, and END.
ASCII to HEX:
TVS = 54 56 53
BEGIN = 42 45 47 49 4e
END = 45 4e 44
We can look for TVS but we might see some false positives.
Instead we want to look for TVS 0x0d 0x0a.
Same with BEGIN

And END

Algorithm:
For EACH_BYTE in TOTAL_BYTES:
Look for HEADER:
Note address of the header
Look for BEGIN:
Note address of begin
Look for FOOTER:
Note address of footer
Extract HEADER to FOOTER & metadata between HEADER and BEGIN.
Implemented in Python:
disk_image = open('myimage','rb').read()
file_number = 1
for i in range(0, len(disk_image)):
if (disk_image[i] == 'T') and (disk_image[i+1] == 'V') and (disk_image[i+2] == 'S') and (disk_image[i+3] == '\x0d') and (disk_image[i+4] == '\x0a'):
header = i
if (disk_image[i] == 'B') and (disk_image[i+1] == 'E') and (disk_image[i+2] == 'G') and (disk_image[i+3] == 'I') and (disk_image[i+3] == 'N') and (disk_image[i+4] == '\x0d') and (disk_image[i+5] == '\x0a') and (disk_image == 'K'):
begin = i
if (disk_image[i] == 'E') and (disk_image[i+1] == 'N') and (disk_image[i+2] == 'D') and (disk_image[i+3] == '\0d') and (disk_image[i+4] == '\0a'):
footer = i+2
outfile = open(str(file_number)+'.tvs', 'wb')
outfile.write(disk_image[header:footer])
outfile.close()
file_number = file_number + 1
The implementation above uses tons of memory.
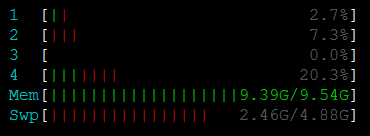
Using the script above would be inefficient.
Regex library in python can be used to make this easier and more efficient.

Headers, begin, and footer are defined.
Addresses for header, begin, and footer are extracted.
TVS file is extracted and written. Metadata is extracted and written.
CPU and Memory usage is low this time and extraction speed is much faster.
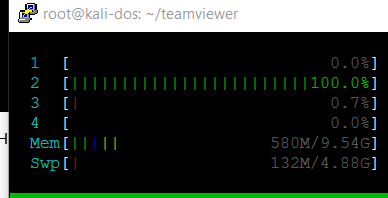

File is uncorrupted and plays with Teamviewer.
That's all. Hopefully that was useful to someone. I'll put the script on https://github.com/ITLivLab/TVS_extractor
Formatting is messed up because copying and pasting doesn't exactly work great between Word, Google Docs, and Blogger.