Part 2: http://www.boredhackerblog.info/2017/05/linux-botnet-malware-analysis-part-2.html
Part 3: http://www.boredhackerblog.info/2017/05/linux-botnet-malware-analysis-part-3.html
Monitoring:
Goal for monitoring was inspired by what MalwareTech has done in the past.
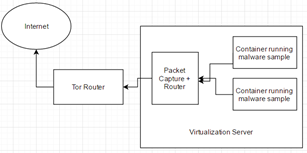
As I stated in the first part, I did want to monitor to see who got attacked by the botnet we were currently researching. While being connected to C2, we did not observe any attack commands being sent.
There are couple of ways you could monitor the specific botnet we were looking at. One way is to just have the client/bot connect to the C2 server and observe the network traffic to see who is getting attacks. In this case, you may want to reduce the network speed to not have large impact. This way is still bad. Another way is to use instrumentation and intercept the C2 commands and write them to file, then modify the command before it’s passed to the actual function that processes the commands. The last way I could think of was to just write a fake bot. This would involve writing something that behaves exactly like the client/bot but doesn’t do all the bad stuff.
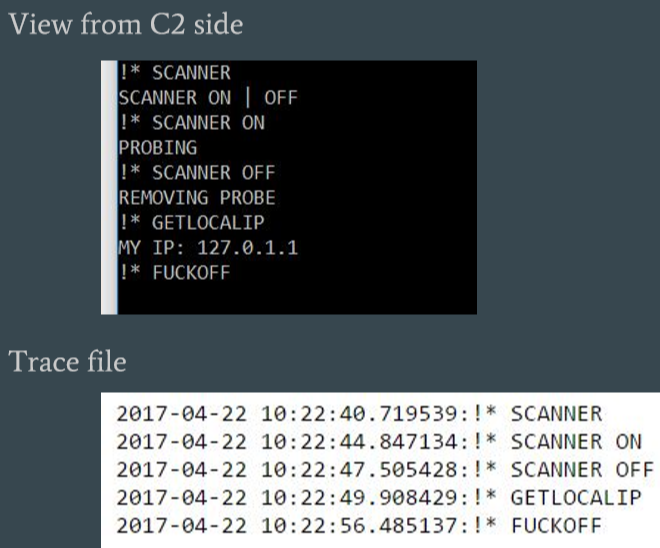
In case of the malware we were analyzing, writing a fake bot was really easy to do due to the simplicity of C2 protocol. Below is the example of the fake bot the specific malware we’re analysing:

When the command from C2 is received, the bot takes timestamp and the command and writes it out into a file so we can keep track of what happened and when it happened.
Limitations and Improvements:
Limitations in this research mostly came from lack of time and lack of skills. We only ran the malware for less than a month and we were not able to observe any actual DDoS attacks.
To improve the research, we could next time monitor multiple botnets to observe actual attacks. We could analyze the malware in more detail as well.
Automation and future research:
When we first ran our honeypots we received a lot of different samples. For automation, we would have to automatically download the malware samples, extract C2 information, and connect to C2 server with fake bot to observe attacks.
For future research, we will try to focus on implementing automation and hopefully see attacks being launched in real time and find out who the victims are.
Conclusion:
This was an interesting semester project. We were able to set up honeypots and get some common malware samples, figure out how they spread and how their brute force algorithm works, we were also able to figure out some of the commands that could be sent to the bots for attacks, and write a monitoring tool.
Resources:
The resources for this project were provided by the Living Lab at IUPUI.